

According to a post on Microsoft’s official developer community blog today, Microsoft has released a new model, Phi-4-Reasoning-Vision-15B, which is a visual reasoning model.
It combines high-resolution visual perception with selective, task-aware reasoning, making it the first small language model (SLM) in the Phi-4 series to simultaneously achieve “seeing clearly” and “thinking deeply”.
Traditional vision models perform only passive perception—identifying “what’s in” an image. Phi-4-Reasoning-Vision-15B goes a step further, performing structured, multi-step reasoning : understanding the visual structure within an image, connecting it to textual context, and deriving actionable conclusions. This enables developers to build intelligent applications ranging from graph analysis to GUI automation.
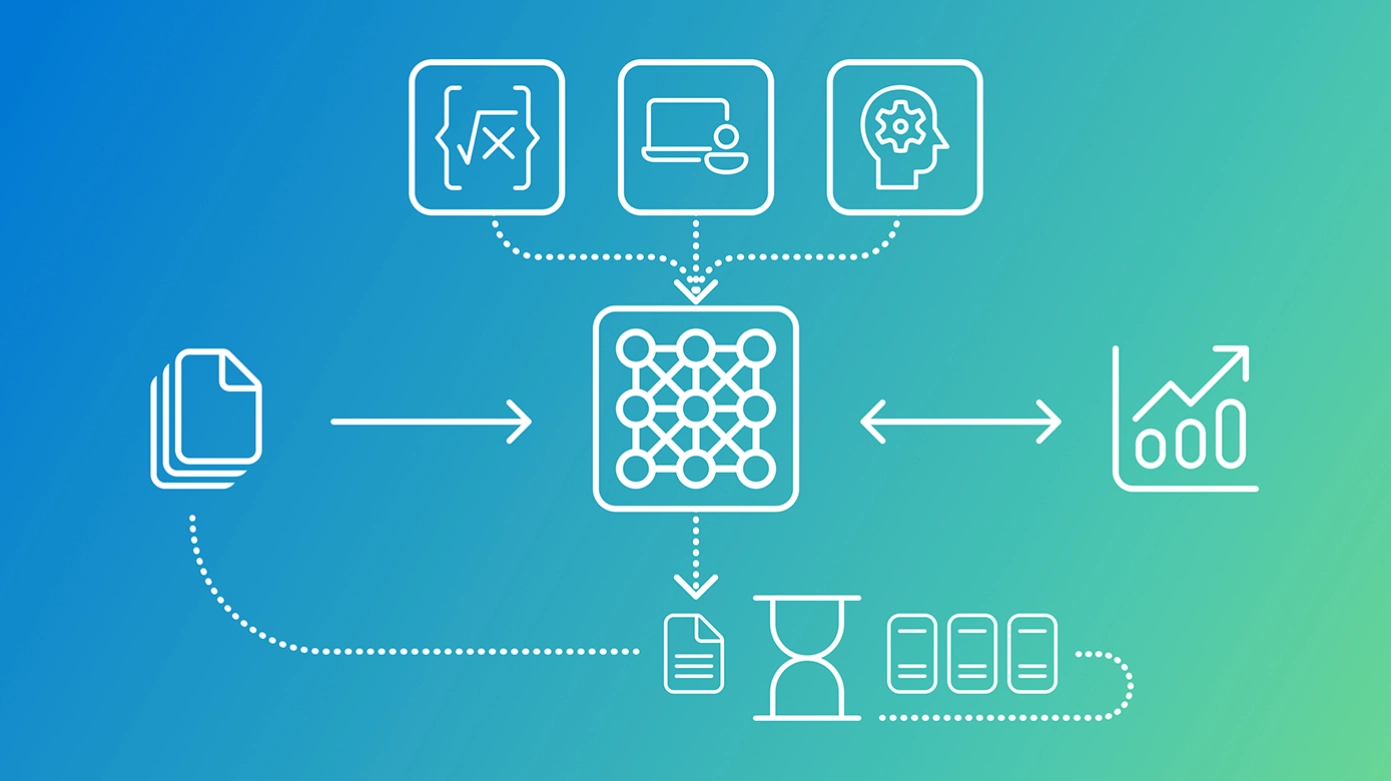
The most critical design feature of this model is its hybrid reasoning behavior. It can switch between “reasoning mode” and “non-reasoning mode” based on prompts:
-
When deep reasoning is required (e.g., mathematical problems, logical analysis) → Enable multi-step reasoning chains
-
When rapid sensing is sufficient (e.g., OCR, element localization) → output directly to reduce latency.
One of the most important applications of this model is in conjunction with computer-intelligent agents. After receiving a screenshot and natural language instructions, the model can output the standardized bounding box coordinates of the target UI element, and other intelligent agent models can perform clicks, scrolling, and other interactions.
The following is a performance comparison of Phi-4-Reasoning-Vision-15B with other models on critical tasks:
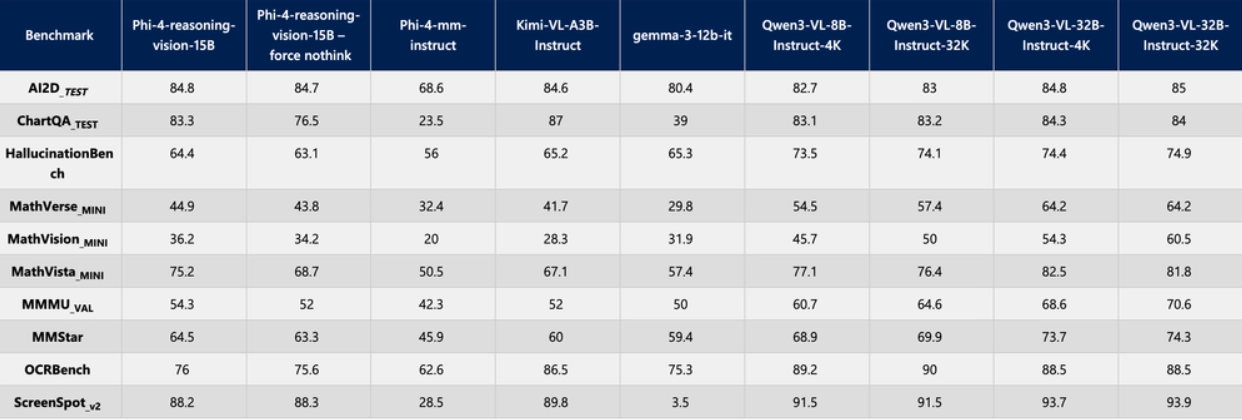
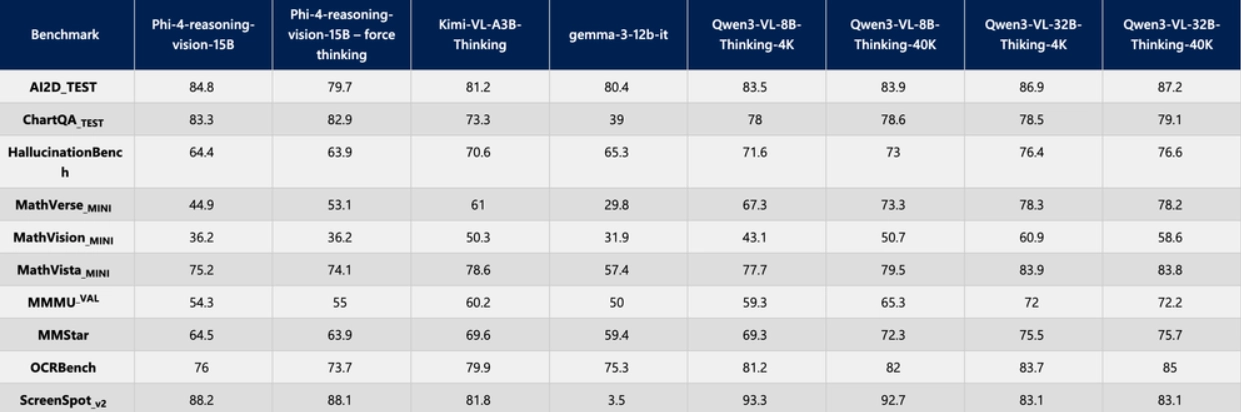
The open-source address is as follows:

