

Xiaomi announced the launch of three major models: MiMo-V2-Pro, Omni, and TTS. These models are currently available on Xiaomi miclaw, MiMo Studio, Kingsoft Office, and Xiaomi Browser, and can be accessed via OpenClaw, OpenCode, KiloCode, Blackbox, and Cline, with a limited-time free trial available for one week.
Xiaomi’s flagship platform model for the Agent era: Xiaomi MiMo-V2-Pro
The Xiaomi MiMo-V2-Pro is designed for high-intensity agent workloads in the real world. It boasts over 1TB of total parameters (42B of activation parameters), employs an innovative hybrid attention architecture, and supports an ultra-long context length of 1MB. Xiaomi continues to scale its computing power across a wider range of agent scenarios, further expanding the intelligent action space and achieving a significant generalization from coding to cracking. On the Artificial Analysis leaderboard, the MiMo-V2-Pro ranks eighth globally and second in China.
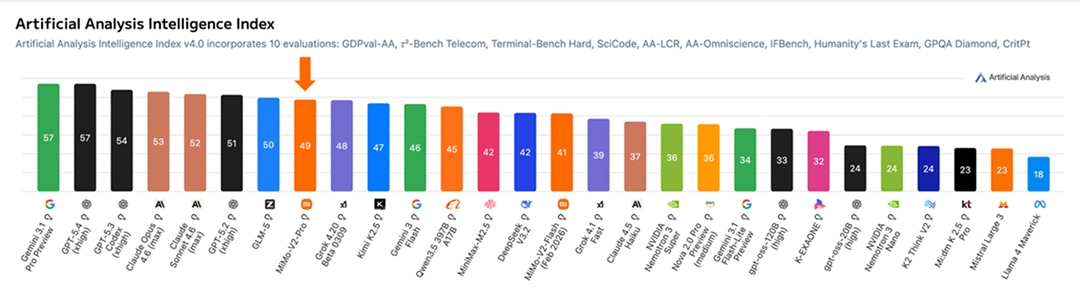
Within intelligent agent frameworks such as OpenClaw and Claude Code, MiMo-V2-Pro can complete complex workflow orchestration, long-term planning, and precise tool invocation without human intervention, consistently and reliably delivering final results. Its overall user experience surpasses Claude Sonnet 4.6 and approaches Opus 4.6, yet its model API is priced at only 1/5 of theirs, lowering the barrier to entry for cutting-edge intelligent systems.
MiMo-V2-Pro is deeply optimized for agent scenarios. It performs SFT & RL on complex and diverse agent scaffolds, possessing enhanced tool invocation and multi-step inference capabilities. On the OpenClaw standard benchmark lists PinchBench and ClawEval, MiMo-V2-Pro’s performance is among the world’s best. Furthermore, with its 1MB context window, MiMo-V2-Pro can easily support high-intensity, complex real-world Claw application flows.
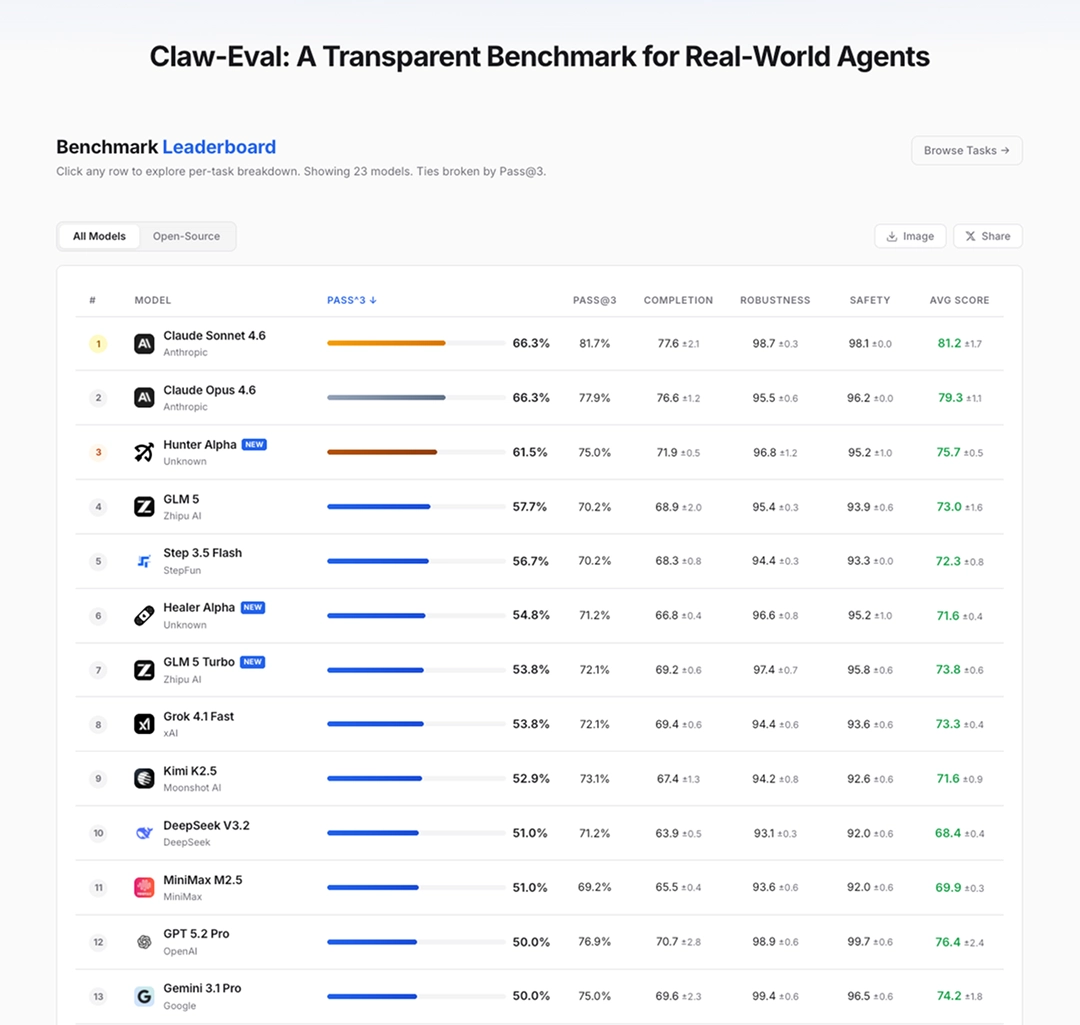
MiMo-V2-Pro is capable of participating in more serious code engineering projects. Internal engineer evaluations show that its performance is close to that of Claude Opus 4.6, and it demonstrates advanced code intelligence: it has better system design and task planning capabilities, a more elegant coding style, and a more efficient and direct problem-solving path.
The MiMo-V2-Pro model is now officially available via API, supporting 1MB context lengths and tiered pricing based on usage.
-
Within 256K context: Input $1 / million tokens, Output $3 / million tokens
-
Within 1M context: Input $2 / million tokens, Output $6 / million tokens
Visit https://platform.xiaomimimo.com to access the API immediately.
The MiMo Claw module is now fully integrated with the Kingsoft WebOffice ecosystem. It natively supports four major formats: Word, Excel, PPT, and PDF, seamlessly covering over 95% of everyday document types.
Xiaomi’s MiMo underlying inference engine has achieved framework-level integration with Kingsoft’s office ecosystem. WPS Lingxi has now integrated the MiMo-V2-Pro model, allowing users to ask questions or assign tasks to Lingxi Claw, making office work more efficient.
Xiaomi’s full-modal base model for the Agent era: Xiaomi MiMo-V2-Omni
It is designed specifically for complex multimodal interaction and execution scenarios in the real world. It can be seamlessly integrated with various agent frameworks, realizing the leap from understanding to control and significantly reducing the threshold for the implementation of full-modal agents.
In terms of audio understanding, it supports everything from ambient sound classification, multi-speaker separation, and audio-visual joint reasoning to deep understanding of over 10 hours of continuous audio. Its overall performance surpasses that of the Gemini 3 Pro, making it one of the most powerful audio understanding foundational models currently available.
In terms of image understanding, MiMo-V2-Omni demonstrates powerful multidisciplinary visual reasoning and complex graph analysis capabilities, surpassing Claude Opus 4.6 and approaching the level of top closed-source models such as Gemini 3 Pro.
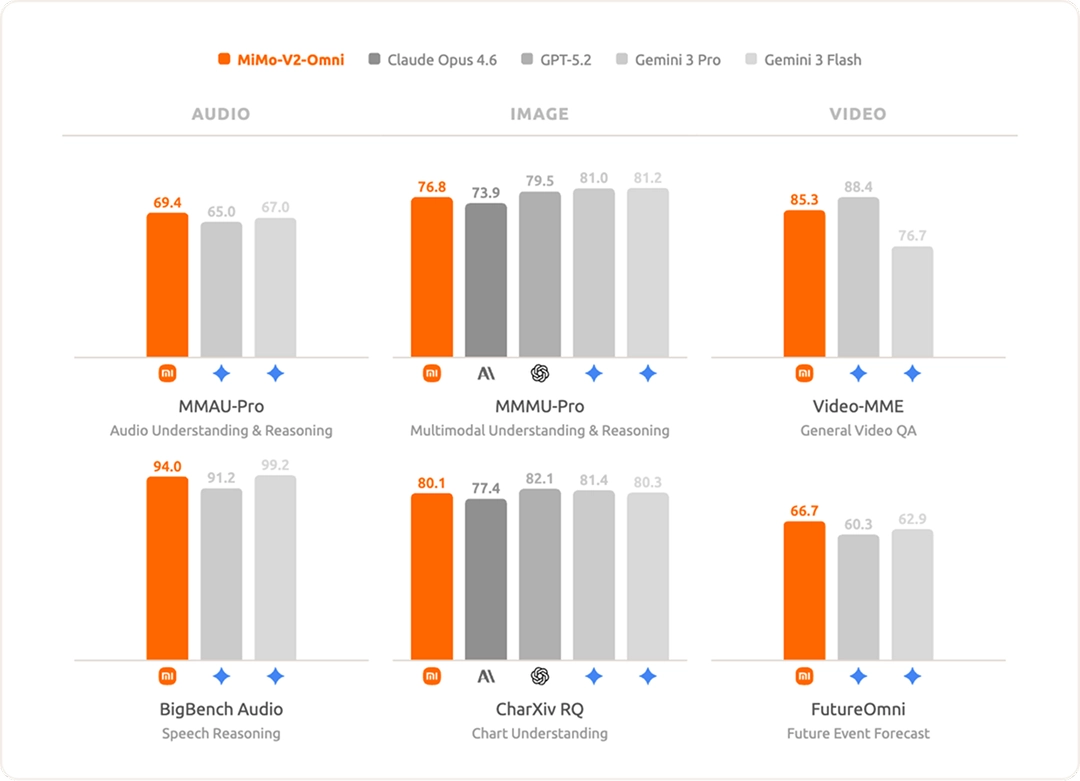
In terms of video understanding, it supports native audio and video joint input, achieving true multimodal video understanding. Through innovative video pre-training, the model possesses powerful context awareness and future reasoning capabilities.
MiMo-V2-Omni is capable of understanding complex environments across modalities, autonomously formulating and executing plans, correcting strategies in real time when encountering anomalies, and ultimately delivering complete results end-to-end.
The MiMo-V2-Omni model is now officially available via API, supporting a 256K context length, input of $0.4 per million tokens, and output of $2 per million tokens.
Visit https://platform.xiaomimimo.com to access the API immediately.
In addition, MiMo-V2-Omni, in collaboration with five major agent development framework teams including OpenClaw, OpenCode, KiloCode, Blackbox, and Cline, is providing global developers with a limited-time free API support for one week.
Designed specifically for multimodal interaction in the Agent era: Xiaomi MiMo-V2-TTS speech synthesis large model
Xiaomi MiMo-V2-TTS is a large-scale speech synthesis model independently developed by Xiaomi. Based on its self-developed Audio Tokenizer and multi-codebook speech-text joint modeling architecture, it has undergone massive pre-training with hundreds of millions of hours of speech data and multi-dimensional reinforcement learning, achieving highly controllable multi-granularity speech style control. MiMo-V2-TTS supports precise adjustment from overall style tone to local emotional expression, completing intonation transitions and emotional shifts within the same sentence; realistically reproducing the natural rhythm of human speech; and accurately expressing pitch and rhythm when singing , naturally and expressively.
During training, MiMo-V2-TTS first learns a powerful unified ability for cross-modal alignment and understanding generation through ultra-large-scale speech-text hybrid pre-training on massive amounts of data; on this basis, through fine-tuning with a small amount of high-quality supervised data, the model obtains generalizable multi-granularity and multi-style instruction control capabilities.
To further unleash the high-performance speech generation potential accumulated during large-scale pre-training, Xiaomi introduced multi-dimensional reinforcement learning, balancing stability and expressiveness. Specifically, during the reinforcement learning phase, MiMo-V2-TTS continuously optimizes multiple dimensions, including more natural prosody, more stable sound quality, more accurate word expression, higher-quality timbre cloning, and appropriate tone and expression in different scenarios. Thanks to its multi-layer codebook modeling architecture, the model models speech in a high-fidelity discrete token space, fully preserving the rich information in the original speech. This allows the reinforcement learning phase to directly utilize speech-related reward signals to optimize the model, enabling multi-dimensional reward signals to more effectively influence the generation process.
MiMo-V2-TTS supports multi-level voice style control from overall to specific. Users can set the overall voice tone through natural language commands, while also adjusting the emotion of specific segments within a sentence in a fine-grained manner, achieving a natural transition between intonation shifts and emotional changes within the same sentence.
The model also boasts rich and diverse expressive capabilities: it supports natural pronunciation in multiple dialects, allows for stylized role-playing performances, and can even achieve high-quality vocal synthesis—allowing the same model to speak, act, and sing, supporting a variety of dialects such as Northeastern Mandarin, Sichuanese, Henan Mandarin, Cantonese, and Taiwanese Mandarin.

